31편. 스레드(Thread) (4)

Callable과 Future
Callable
기억을 되살려서 Runnable이 무엇이었는지 떠올려 봅시다. 전에 사용했던 Runnable은 실행이 끝난 후에 어떤 결과 값을 반환해 줄 수 없었으며, 예외가 발생할 수 있다고 throws 문을 통해서 표현할 수도 없었습니다. 하지만 Callable을 사용하면 결과 값도 돌려줄 수 있으며, 예외도 발생시킬 수 있도록 만들 수 있습니다.
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
@FunctionalInterface
public interface Callable<V> {
// 계산한 결과를 반환할 수 있는 메서드다.
// 만약에 결과를 계산할 수 없으면 예외를 던질 수 있다.
V call() throws Exception;
}하지만 Thread는 Runnable 타입을 매개변수로 받고 있어서 Callable을 직접적으로 전달할 수는 없습니다. 그러면 어떻게 해야 할까요? 이런 경우에는 바로 FutureTask를 사용할 수 있습니다. 그 전에 설명의 편의와 이해를 돕기 위해서 블로킹/논블로킹, 동기/비동기가 무엇인지 설명을 하고, Future와 Task가 무엇인지 살펴보도록 하겠습니다.
public class Thread implements Runnable {
public Thread(Runnable target) {
this(null, target, "Thread-" + nextThreadNum(), 0);
}
// ...
}블로킹과 논블로킹
실행의 흐름을 중단시키는지, 다시 말해서 다른 주체가 작업을 하고 있을 때 제어권이 나 자신에게 있는지에 따라서 블로킹(blocking)과 논블로킹(non-blocking)으로 나눌 수 있습니다.
동기와 블로킹, 그리고 비동기와 논블로킹
여기서 주의할 점은 이어서 소개할 동기(synchronous)는 블로킹(blocking)과 자주 어울리고, 비동기(asynchrnous)는 논블로킹(non-blocking)과 자주 어울리지만 동기와 블로킹, 비동기와 논블로킹에는 맥락에 따라서 미묘한 차이가 존재합니다. 굳이 말하면 어디를 중요하게 보느냐와 같은 관점의 차이라고 할 수 있겠습니다.
블로킹(blocking)
만약 실행의 흐름이 중단되고, 다른 사람이 하는 일이 끝날 때까지 기다린 후에 다시 자신의 작업을 이어간다면 블로킹(blocking)이라고 할 수 있습니다.

좀 더 프로그래머의 관점으로 끌어들이면, 어떤 메서드를 호출하고 제어권이 자신에게 곧바로 돌아오는지 아닌지에 따라 블로킹이 발생할 수 있습니다. 만약 메서드가 실행 중에 다른 메서드를 호출하고, 호출된 메서드에서 다른 작업을 수행하지 못하고 제어권이 반환될 때까지 기다려야 한다면 블로킹이 발생한다고 할 수 있습니다.
제어권(control flow)
프로그램의 실행 흐름을 결정하는 권한을 말합니다. 프로그래밍에서 어떤 코드 블록이나 메서드가 실행되어야 할지를 결정하는 것이 제어권에 해당합니다.
제어권을 넘긴다는 것은 코드 실행의 흐름을 다른 코드 블록이나 메서드에게 전달하는 것을 말합니다. 예를 들어서, 어떤 메서드를 호출하면 그 메서드에게 제어권을 넘겨줌으로써 해당 메서드의 코드를 실행할 수 있게 됩니다. 메서드의 실행이 모두 끝나면 제어권은 원래 위치로 돌아오게 됩니다.
public class SynchronousBlockingExample {
public static void main(String[] args) {
System.out.println("블로킹 연산을 실행 중 ...");
// 제어권이 상대방에게 넘어감
synchronousBlocking();
// 제어권이 자신에게 돌아옴
System.out.println("블로킹 연산이 끝났습니다.");
}
public static void synchronousBlocking() {
try {
// 블로킹 연산을 시뮬레이션 하기 위해서 Thread.sleep() 사용
Thread.sleep(5000); // 5초동안 블록됨
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}논블로킹(non-blocking)
만약 실행의 흐름이 중단되지 않고, 다른 사람이 하는 작업과 무관하게 자신의 작업을 계속한다면 이는 논블로킹(non-blocking)이라고 할 수 있습니다.
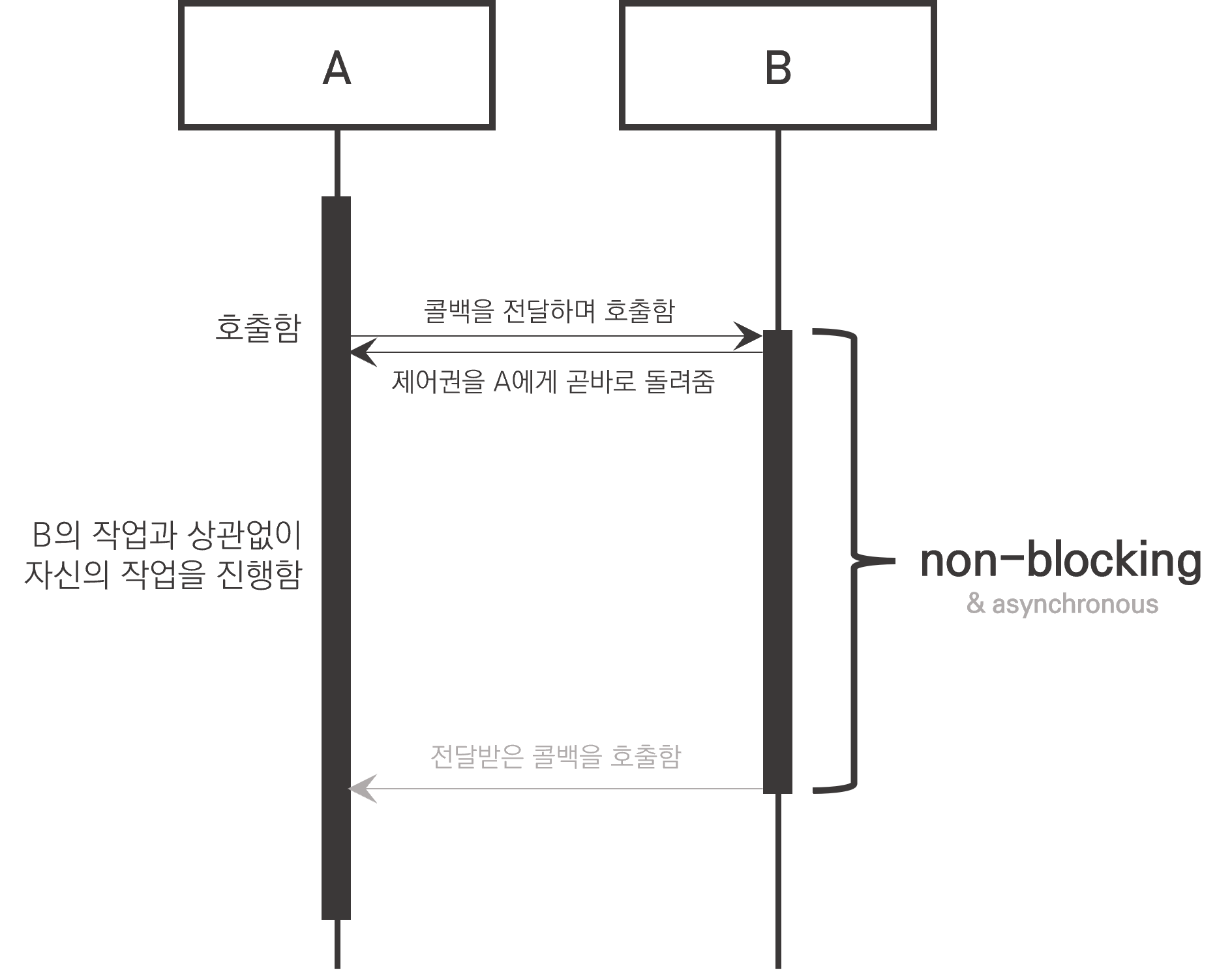
다시 프로그래머의 관점으로 끌어들이면, 어떤 메서드를 호출하고 제어권을 곧바로 돌려받은 뒤 다른 작업을 수행할 수 있는 것을 의미합니다. 좀 더 자세하게 말하면 위 그림에서 A가 B를 호출했을 때 그 시점에서 가지고 올 수 있는 데이터(그게 전체 데이터인지 일부 데이터인지는 상관없이)를 가지고 즉각적으로 제어권을 돌려받게 됩니다. 설명의 편의를 위해서 CompletableFuture와 람다식을 사용했는데 이에 대해서는 내용이 길어질 것 같아 별도의 게시글에서 다루도록 하겠습니다.
콜백(callback)
콜백(callback)은 실행되는 것을 목적으로 다른 객체의 메서드에 전달되는 객체를 말합니다. 매개변수로 전달되지만 값을 참조하기 위한 것이 아니라 특정 로직을 담은 메서드를 실행시키기 위해 사용됩니다.
import java.util.concurrent.CompletableFuture;
public class AsynchronousNonBlockingExample {
public static void main(String[] args) {
System.out.println("논블로킹 연산을 실행 중...");
// 논블로킹 연산을 시뮬레이션 하기 위해서 CompletableFuture를 사용함
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(5000); // 5초 동안 블로킹
} catch (InterruptedException e) {
e.printStackTrace();
}
});
future.whenComplete((result, error) -> {
if (error != null) {
System.err.println("논블로킹 연산 도중 에러가 발생함: " + error.getMessage());
} else {
System.out.println("논블로킹 연산이 성공적으로 완료됨");
}
});
System.out.println("메인 스레드는 계속해서 실행됨...");
// 논블로킹 연산이 끝나기를 기다림
// 이게 없으면 메인 스레드가 곧바로 종료되어 논블로킹 연산이 완료되는 걸 볼 수 없음
future.join(); // 이것 자체는 블로킹 연산
}
}동기와 비동기
블로킹과 논블로킹이 실행의 흐름이 중단되는지 혹은 제어권이 나에게 있는지 없는지에 중점을 두는 반면에, (적어도 프로그래밍의 맥락에서) 동기와 비동기는 순차적으로 실행되는가와 같은 실행의 순서 혹은 처리해야 할 작업에 관심이 있는지 없는지와 같은 작업의 결과에 중점을 두고 있습니다.
동기(synchronous)
동기(synchronous)에서는 순차적으로 작업이 실행됩니다. 즉, 작업의 순서가 보장된다고 할 수 있습니다. 이는 이전 단계가 끝나기 전까지는 다음 단계로는 넘어갈 수 없다는 의미입니다. 바꿔 말하면 처리해야 할 이전 작업이 완료되었는지에 대해 관심을 갖고 있다고 할 수 있습니다.

예를 들어서 아래와 같은 상황을 생각해봅시다. 여기에서는 손님이 자리를 찾고, 메뉴를 고르고, 음식을 주문하고, 계산을 하는 동기적인 상황을 보여주고 있습니다. 손님은 주인이 자리를 찾아주거나 주문을 처리하는 등의 일을 처리할 때까지 기다리며 다른 일을 하지 않습니다.
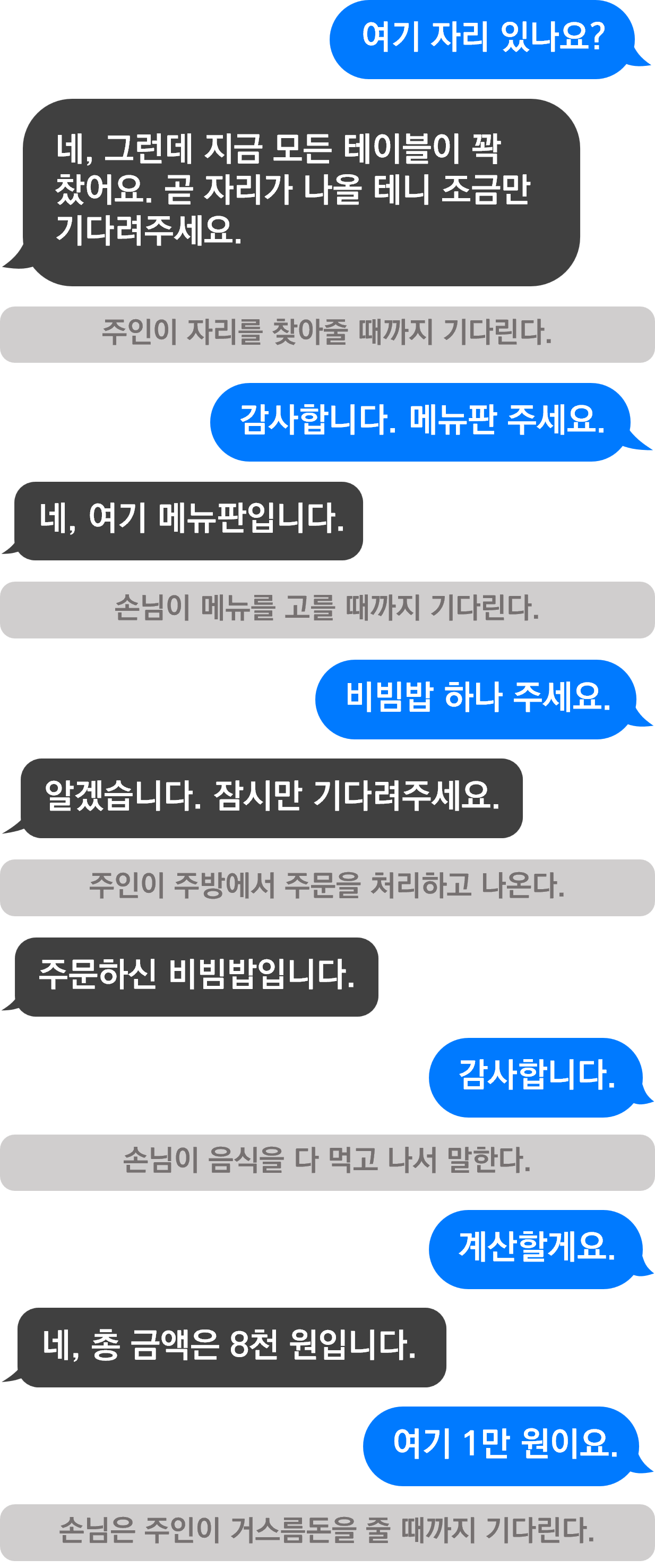
아래는 동기와 논블로킹의 조합을 보여주는 예시입니다. 다른 스레드의 작업을 모두 마칠 때까지 계속 끝났는지 물어보지만, 제어권을 바로 돌려받으면서 여전히 다른 일을 할 수 있는 것을 볼 수 있습니다.
import java.util.concurrent.*;
public class SynchronousNonBlockingExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<String> task = () -> {
System.out.println("작업이 시작됨...");
TimeUnit.SECONDS.sleep(2); // 뭔가 긴 연산
System.out.println("작업이 끝남...");
return "작업 결과";
};
Future<String> future = executor.submit(task);
// 폴링(polling) 방식으로 상대방의 작업이 끝났는지 주기적으로 확인함
while (!future.isDone()) {
System.out.println("메인 스레드는 블록되지 않으며 여전히 다른 작업을 할 수 있음...");
try {
TimeUnit.MILLISECONDS.sleep(500); // 뭔가 작업함
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
String result = future.get();
System.out.println("작업 결과: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
executor.shutdown();
}
}폴링(polling)
하나의 장치(혹은 프로그램)가 충돌 회피 혹은 동기화 처리 등을 목적으로 다른 장치(혹은 프로그램)의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식을 말합니다.
비동기(asynchronous)
비동기(asynchronous)에서는 순서가 흐트러질 수 있으며 엄격한 순서를 따를 필요가 없습니다. 다시 말해서 별도의 시작 시간과 종료 시간을 가질 수 있다는 말이며, 여기서는 처리해야 할 작업이 완료되었는지 완료되지 않았는지는 크게 관심이 없습니다. 작업이 완료됐다는 사실은 콜백을 호출하거나 인터럽트를 걸거나 하는 것과 같이 별도의 알림을 보내줌으로써 알려주게 됩니다.

아래 상황을 예시로 들어봅시다. 이 상황에서는 손님이 세탁소에 세탁물을 맡기고, 직원이 세탁 작업을 완료할 때까지 기다리지 않고 다른 일을 계속 진행하는 비동기적인 상황을 보여줍니다. 손님은 현재 세탁소 직원이 세탁을 모두 끝냈는지에 대해서는 크게 관심이 없습니다. 손님은 세탁 작업이 완료되는 동안 다른 일을 처리하고, 세탁물이 준비되면 문자 알림을 통해서 알게 됩니다. 손님이 문자를 확인하고 바로 세탁물을 가지러 가거나, 바쁜 상황이라 문자(콜백)를 확인하지 않고 다른 일을 계속 처리할 수도 있습니다.

잠시만요, 비동기와 블로킹 조합은 어디갔나요?
동기는 대개 블로킹, 비동기는 대개 논블로킹과 어울립니다. 사실상 동기와 논블로킹, 비동기와 블로킹은 흔히 있는 조합은 아닙니다. 특히 비동기와 블로킹 조합은 비효율적이라 더더욱 그렇습니다.

블로킹이라 제어권을 곧바로 돌려받지 못하지만, 비동기라 서로의 작업에 그렇게 크게 관심이 없습니다. 작업이 언제 끝나는지 관심이 없는데도 그 사람의 작업이 끝나야 다른 작업을 이어서 할 수 있습니다. 이는 사실상 동기와 블로킹 조합과 유사하게 진행됩니다. 보통 잘못된 코드 구조나 개발자의 실수 등으로 인해서 일어나는데, 대표적인 예시로 블로킹 방식의 MySQL 드라이버와 싱글 스레드 기반의 비동기 방식인 Node.js의 조합이 있다고 합니다.
Future
이제 다시 돌아와서 Future를 살펴보도록 하겠습니다. Future는 비동기적으로 이루어지는 계산의 처리 결과를 나타냅니다. 다시 말해서 아직 계산되지 않았지만 "미래(future)"의 어느 시점에 사용할 수 있는 값을 나타냅니다.
public interface Future<V> {
// 현재 작업의 실행을 취소하려고 시도한다.
// mayInterruptIfRunning가 true인 경우:
// 작업을 중단하려고 시도하며 작업이 중단되면 InterruptedException이 발생할 수 있다.
// mayInterruptIfRunning가 false인 경우:
// 작업이 실행 중이지 않고 아직 시작되지 않았으면 작업을 취소한다.
// 그러나 작업이 이미 실행 중이라면 작업을 중단하지 않고 계속 실행된다.
boolean cancel(boolean mayInterruptIfRunning);
// 이 작업이 정상적으로 완료되기 전에 취소된 경우 true를 반환한다.
boolean isCancelled();
// 이 작업이 완료되면 true를 반환한다.
// 여기서 완료는 '정상적인 종료', '예외', '취소'로 인한 것일 수 있으며
// 이 모든 경우에 이 메서드는 true를 반환한다.
boolean isDone();
// 비동기 작업의 결과를 반환한다.
// 작업이 아직 완료되지 않았다면, 작업이 완료될 때까지 현재 스레드를 블록한다.
// 작업 중 예외가 발생하면 ExecutionException이 발생한다.
// 작업이 취소된 경우에는 CancellationException이 발생한다.
V get() throws InterruptedException, ExecutionException,
CancellationException; // 블로킹 호출
// 지정된 시간만큼 작업의 결과를 기다린 후 반환한다.
// 만약 작업이 완료되기 전에 시간이 초과되면 TimeoutException이 발생한다.
V get(long timeout, TimeUnit unit) // 블로킹 호출
throws InterruptedException, ExecutionException,
CancellationException, TimeoutException;
}Future를 통해서 특정 작업이 정상적으로 완료됐는지, 아니면 취소됐는지 등에 대한 정보를 확인할 수 있습니다. Future가 동작하는 사이클에서 염두에 두어야 할 점은, 한 번 지나간 상태는 되돌릴 수 없다는 점입니다. 일단 완료된 작업은 완료 상태에 영원히 머무르게 됩니다.
아래 예시에서는 Future를 사용해서 간단한 비동기 작업을 수행하고 있는 걸 볼 수 있습니다. 아래 예제에서는 두 개의 숫자를 더하는 작업을 비동기적으로 수행하고 결과를 가져옵니다.
public class FutureExample {
public static void main(String[] args) {
// 스레드 풀에 대해서는 후반에 같이 살펴보겠습니다.
// 지금은 그냥 스레드라고 생각을 해주세요.
ExecutorService executorService = Executors.newFixedThreadPool(1);
// 비동기 작업 정의
Callable<Integer> additionTask = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int a = 5;
int b = 7;
int result = a + b;
System.out.println("덧셈 작업이 완료되었습니다.");
return result;
}
};
// 비동기 작업 실행 및 결과를 저장하는 Future 객체 얻기
Future<Integer> futureResult = executorService.submit(additionTask);
while (!futureResult.isDone()) {
System.out.println("덧셈 작업이 완료되기를 기다리는 중...");
try {
// 일정 시간동안 대기한 후 다시 작업 완료 여부를 확인한다.
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
// 비동기 작업 결과 가져오기
Integer result = futureResult.get(1, TimeUnit.SECONDS);
System.out.println("덧셈 결과: " + result);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
e.printStackTrace();
} finally {
// ExecutorService 종료
executorService.shutdown();
}
}
}FutureTask
FutureTask는 Future, Runnable을 상속받는 RunnableFuture 인터페이스의 기본 구현체입니다. FutureTask도 Future와 마찬가지로 한 번 종료됨 상태에 이르고 나면 더 이상 상태가 바뀌는 일은 없습니다. FutureTask는 기타 시간이 많이 필요한 모든 작업이 있을 때 실제 결과가 필요한 시점 이전에 미리 작업을 실행시켜두는 용도로 사용합니다.
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
public class FutureTask<V> implements RunnableFuture<V> {
/* ... Future와 동일 ... */
}아래 예시에서는 웹 페이지의 내용을 가져오는 작업을 비동기적으로 수행합니다. Callable 객체를 정의한 다음에 이를 FutureTask로 감싸서 Thread로 넘기고 있는 것을 볼 수 있습니다. 작업이 완료되면 futureTask.get()을 호출해서 웹 페이지의 내용을 가져올 수 있습니다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class FutureTaskThreadNonBlockingExample {
public static void main(String[] args) {
// 비동기 작업 정의
Callable<String> fetchWebPageTask = new Callable<String>() {
@Override
public String call() throws Exception {
String urlToRead = "https://www.example.com";
URL url = new URL(urlToRead);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
StringBuilder result = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
result.append(line);
}
reader.close();
System.out.println("웹 페이지를 가져오는 작업이 완료되었습니다.");
return result.toString();
}
};
// FutureTask 객체 생성
FutureTask<String> futureTask = new FutureTask<>(fetchWebPageTask);
// 새로운 Thread를 생성하고 FutureTask를 실행한다.
Thread taskThread = new Thread(futureTask);
taskThread.start();
// 다른 작업 수행 (예: 데이터 처리)
System.out.println("다른 작업 중 ...");
while (!futureTask.isDone()) {
System.out.println("웹 페이지를 가져오는 작업이 완료되기를 기다리는 중...");
try {
// 일정 시간동안 대기한 후 다시 작업 완료 여부를 확인한다.
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
// 비동기 작업 결과 가져오기
String webPageContent = futureTask.get();
System.out.println("웹 페이지 내용: " + webPageContent);
} catch (Exception e) {
e.printStackTrace();
}
}
}스레드 풀(Thread Pool)
스레드 풀의 등장 배경
스레드 풀은 도대체 무엇일까요? 스레드들이 뛰어노는 수영장(pool)? 얼추 비슷하다고 할 수 있습니다. 이를 스레드 풀의 이름과 수영장을 연관 지어서 좀 더 친숙한 예시를 들어보자면, 스레드 풀은 마치 여러 수영 선수들이 대기하고 있는 수영장과 비슷합니다.

수영 대회에서 각 경기가 차례대로 진행될 때, 수영 선수들은 미리 대기하고 있는 수영장에서 다음 경기를 기다리며 준비합니다. 매 경기마다 새로운 선수를 찾아서 고용하는 게 아니라, 이미 대기하고 있는 선수들 중에서 필요한 선수를 빠르게 배치하여 경기가 원활하게 진행하도록 만듭니다.
스레드 풀도 이와 비슷한 원리로 동작합니다. 여러 작업을 동시에 처리해야 할 때, 매번 새로운 스레드를 생성하고 종료하는 것은 컴퓨터 입장에서 많은 시간과 자원을 소모합니다. 이런 문제를 해결하기 위해서 미리 생성된 스레드들을 '풀(pool)'에 보관하고, 작업이 발생할 때마다 스레드 풀에서 이용 가능한 스레드를 가져와 작업을 처리하게 됩니다. 작업이 끝난 스레드는 다시 스레드 풀로 돌아와서 다음 작업을 기다리게 됩니다.
이렇게 스레드 풀을 사용함으로써, 프로그램은 재사용으로 스레드 생성과 종료에 드는 비용을 절약하고, 자원을 효율적으로 활용하여 전체 성능을 높일 수 있습니다. 거기에다가 만약에 어떤 요청이 들어와서 즉시 작업을 수행해야 할 때, 해당 요청을 처리할 스레드가 이미 만들어진 상태로 대기하고 있기 때문에 작업을 실행하는 데 딜레이가 발생하지 않아 전체적인 반응 속도도 올라가게 됩니다.
ExecutorService
자바에서 Executors와 ExecutorService를 이용하면 복잡한 스레드 관리와 병렬 작업 처리를 단순화하고, 간단하게 스레드 풀을 만들고 관리할 수 있습니다.
ExecutorService는 비동기 작업의 진행 상황을 추적하는 Future를 만들 수 있는 메서드와 종료를 제어하는 메서드를 제공합니다. 작업의 종료를 위해서 shutdown(), shutdownNow() 메서드를 제공하고, 일괄 작업 처리를 위해서 invokeAny(), invokeAll() 메서드를 사용할 수 있습니다. 또한 submit() 메서드를 통해 작업을 제출할 수 있습니다. 또한 submit()을 통해 작업을 제출할 수도 있습니다. 여기서 제출한다는 의미는 작업을 스레드 풀에 추가하여 스레드가 처리하도록 요청하는 것을 말합니다.
public interface ExecutorService extends Executor {
// 실행 중인 모든 작업이 완료된 후에 스레드 풀을 종료하도록 요청한다.
// 이 메서드가 호출된 후에는 새로운 작업을 제출(submit)할 수 없다.
// 이 메서드는 실행 중인 작업이 종료될 때까지 기다리지 않는다.
void shutdown();
// 실행 중인 모든 작업을 중지하고 실행 대기 중이던 작업 리스트를 반환한다.
// 이 메서드는 실행 중인 작업이 종료될 때까지 기다리지 않는다.
List<Runnable> shutdownNow();
// ExecutorService가 종료 요청을 받았는지 확인한다.
boolean isShutdown();
// ExecutorService가 완전히 종료되었는지 확인한다.
boolean isTerminated();
// 주어진 시간 동안 ExecutorService의 종료를 대기한다.
// 이 메서드를 사용하면 스레드 풀이 종료될 때까지 대기한 다음 다른 작업을 계속할 수 있다.
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
// ExecutorService에 작업을 제출하며, 작업이 스레드 풀에서 병렬로 실행된다.
// 작업이 제출되면 ExecutorService는 작업을 큐에 추가하고
// 사용 가능한 스레드가 있으면 작업을 실행한다.
// submit() 메서드는 Future<T> 객체를 반환하며 이를 통해서
// 작업의 결과를 확인하거나 작업이 완료되었는지 확인할 수 있다.
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
// 주어진 모든 작업을 실행하고 각 작업의 결과를 담은 Future<T> 객체의 리스트를 반환한다.
// 이 메서드는 모든 작업이 완료될 때까지 블로킹된다.
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 주어진 작업 목록 중 하나가 성공적으로 완료될 때까지 블로킹되며,
// 완료된 작업의 결과를 반환한다. 이 메서드는 주어진 작업들을
// 병렬로 실행하고, 가장 먼저 완료된 작업의 결과를 사용하려는 경우에 유용하다.
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}Executors
자바에서는 흔하게 사용하는 여러 가지 설정에 맞춰서 다양한 스레드 풀을 제공하고 있습니다. 미리 정의된 스레드 풀을 사용하려면 Executors 클래스를 사용할 수 있습니다. 아래의 메서드들을 차근차근 살펴보도록 하겠습니다. 참고로, Executors 유틸리티 클래스에서는 ExecutorService 뿐만 아니라 Executor, ScheduledExecutorService, ThreadFactory, Callable에 대한 팩토리 메서드도 제공하고 있습니다.
팩토리 메서드(factory method)
객체를 생성하는 메서드를 말합니다. 이 메서드는 특정 인터페이스나 클래스의 인스턴스를 초기화하는 역할을 담당합니다. 팩토리 메서드를 사용하면 클래스 외부에서 생성자를 직접 호출하는 대신, 객체 생성에 필요한 로직을 캡슐화해서 객체 생성을 단순화하고 유연성을 제공할 수 있습니다.
newFixedThreadPool
말 그대로 고정된 크기의 스레드 풀을 생성할 수 있습니다. 어떤 시점에서든 최대 nThreads개의 스레드만 작업을 처리할 수 있습니다.

모든 스레드가 작업을 처리 중인 상태에서 추가 작업을 제출하면, 작업을 끝낸 스레드가 생길 때까지 크기가 무제한인 공유 작업 큐에서 대기하게 됩니다. 만약, 실행 중 오류로 인해 스레드가 종료되면 새로운 스레드가 생성되어 대기 중인 작업을 처리합니다.
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newCachedThreadPool
말 그대로 캐시된 스레드 풀을 생성할 수 있습니다. 이 풀은 필요에 따라서 스레드를 생성하고, 사용되지 않는 스레드는 캐시에서 제거합니다. 다시 말해서, 풀에 갖고 있는 스레드의 수가 처리할 작업의 수보다 많아서 쉬는 스레드(60초 동안 사용되지 않는 스레드)가 많아지면 쉬는 스레드를 종료시키며, 처리할 작업의 수가 많아지면 필요한 만큼 스레드를 새로 생성하게 됩니다.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}여기서 ThreadPoolExecutor의 두 번째 인자는 maximumPoolSize인데 이는 풀에서 허용하는 최대 스레드의 수를 말합니다. 즉, 이게 Integer.MAX_VALUE라는 의미는 스레드의 수에 제한을 두지 않는다는 것입니다. 따라서 요청의 수가 많아지면 무한정으로 스레드를 생성할 수 있게 되므로 주의가 필요합니다.
newSingleThreadExecutor
newSingleThreadExecutor는 하나의 스레드를 사용하는 스레드 풀입니다. 즉, 한 번에 하나의 작업만 수행할 수 있습니다. 만약 작업 도중에 예외가 발생해서 비정상적으로 종료되면 새로운 스레드를 생성하여 나머지 작업을 실행합니다. 또한, 등록된 작업은 반드시 순차적으로 처리됩니다.
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}newScheduledThreadPool
newScheduledThreadPool 스레드 풀은 주기적으로 실행하거나 일정 시간 이후에 실행하는 작업을 실행할 수 있습니다.
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}예시 살펴보기
고정된 스레드 풀을 사용하는 간단한 예시
아래 예시에서는 newFixedThreadPool을 사용해서 고정된 크기의 스레드 풀을 사용하여 5개의 작업을 동시에 실행하는 코드를 볼 수 있습니다. 그 후, shutdown()을 호출해서 ExecutorService를 종료하게 됩니다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolExample {
public static void main(String[] args) {
// 고정 크기의 스레드 풀 생성 (크기: 5)
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 10개의 작업을 스레드 풀에 제출
for (int i = 0; i < 10; i++) {
final int taskId = i + 1;
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 스레드에서 작업 " + taskId + "을 실행 중입니다...");
try {
// 각 작업이 2초간 실행되도록 시뮬레이션
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 스레드에서 작업 " + taskId + "을 완료했습니다.");
}
});
}
// 모든 작업이 완료되면 ExecutorService를 종료
executorService.shutdown();
}
}캐시된 스레드 풀을 사용하여 소수를 찾는 예시
아래 예시에서는 newCachedThreadPool을 사용해서 여러 숫자 범위 내의 소수를 찾는 작업을 동시에 수행합니다. 각 작업은 주어진 범위 내에서 소수를 찾아 리스트에 추가하고 반환하게 됩니다. 작업 리스트가 완료되면 결과를 출력하고 ExecutorService가 종료됩니다.
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
public class CachedThreadPoolPrimeExample {
public static void main(String[] args) {
// 캐시된 스레드 풀 생성
ExecutorService executorService = Executors.newCachedThreadPool();
// 숫자 범위 목록 생성
int[][] ranges = {{2, 1000000}, {1000001, 2000000}, {2000001, 3000000}, {3000001, 4000000}, {4000001, 5000000}};
// Callable 작업 목록 생성
List<Callable<List<Integer>>> tasks = new ArrayList<>();
for (int[] range : ranges) {
tasks.add(new Callable<List<Integer>>() {
@Override
public List<Integer> call() throws Exception {
return findPrimesInRange(range[0], range[1]);
}
});
}
// 작업 목록을 스레드 풀에 제출하고 결과를 처리
long startTime = System.nanoTime();
try {
List<Future<List<Integer>>> results = executorService.invokeAll(tasks);
for (Future<List<Integer>> result : results) {
System.out.println("찾은 소수: " + result.get());
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
long endTime = System.nanoTime();
long durationInMillis = TimeUnit.NANOSECONDS.toMillis(endTime - startTime);
System.out.println("수행 시간: " + durationInMillis + "ms");
// 모든 작업이 완료되면 ExecutorService를 종료
executorService.shutdown();
}
// 주어진 범위에서 소수를 찾는 메서드
public static List<Integer> findPrimesInRange(int start, int end) {
List<Integer> primes = new ArrayList<>();
for (int i = start; i <= end; i++) {
if (isPrime(i)) {
primes.add(i);
}
}
return primes;
}
// 소수 판별 메서드
public static boolean isPrime(int number) {
if (number <= 1) {
return false;
}
for (int i = 2; i <= Math.sqrt(number); i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
}ThreadLocal
ThreadLocal을 사용하면 손쉽게 스레드 로컬 변수를 만들 수 있습니다. 스레드 로컬 변수는 하나의 스레드에서만 사용할 수 있는 변수를 말합니다. ThreadLocal 클래스에는 get()과 set() 메서드가 있는데 호출하는 스레드마다 다른 값을 사용할 수 있도록 관리해줍니다.
public class ThreadLocal<T> {
// 현재 실행 중인 스레드에서 최근에 set() 메서드를 호출해 저장했던 값을 가져온다.
public T get() { /* ... */ }
// 현재 실행 중인 스레드의 로컬 변수에 값을 설정한다.
public void set(T value) { /* ... */ }
// 현재 실행 중인 스레드의 로컬 변수 값을 제거한다.
// 이렇게 하면 해당 변수에 대한 현재 스레드의 값이 사라지고,
// 다음 get() 호출 시 initialValue() 메서드를 통해 초기값이 다시 설정된다.
public void remove() { /* ... */ }
// ...
}내부 동작
ThreadLocal의 내부를 보면 간단명료하게 만들어진 것을 볼 수 있습니다. 처음으로 get() 메서드가 호출되면 ThreadLocal의 값은 initialValue() 메서드가 반환하는 값으로 초기화됩니다. 그 후로는 ThreadLocal의 값은 각각의 스레드마다 독립적으로 유지되며, set() 메서드를 호출하여 값을 변경할 수 있습니다. 이때 set() 메서드를 호출한 스레드에서만 해당 값이 변경되고, 다른 스레드에는 영향을 주지 않습니다.
public class ThreadLocal<T> {
// ...
public T get() {
// 현재 실행 중인 스레드를 가져온다.
Thread t = Thread.currentThread();
// 스레드 로컬 값을 저장하는데 사용되는 해시 맵이다.
ThreadLocalMap map = getMap(t);
if (map != null) {
// 스레드 로컬 객체를 키로 키-값 쌍을 가져온다.
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
// 키(스레드 로컬 객체)에 매핑된 값을 반환한다.
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 기본적으로 초기값은 null이다.
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
// 이 스레드 로컬 변수에 대한 현재 스레드의 초기 값을 반환한다.
// 스레드가 이전에 set() 메서드를 호출한 경우가 아니면,
// 스레드가 get() 메서드를 통해 변수에 처음 접근할 때 이 메서드가 호출된다.
// 이 구현은 null만 반환하며, null이 아닌 초기값을 가지고 싶다면
// 개발자가 ThreadLocal을 상속받아서 오버라이딩해야 한다.
protected T initialValue() {
return null;
}
}Thread 클래스 내부를 살펴보면 아래와 같이 threadLocals를 멤버로 갖고 있음을 볼 수 있습니다. ThreadLocal을 통해 저장했던 값들이 이 ThreadLocalMap으로 들어가게 됩니다. 이는 일종의 해시 맵으로 스레드 로컬 변수를 저장하기 위해 만들어진 간단한 자료구조입니다.
public class Thread implements Runnable {
// ...
ThreadLocal.ThreadLocalMap threadLocals = null;
}예시 살펴보기
아래 예시에서는 초기값을 반환하는 initialValue() 메서드를 오버라이딩하여 각 스레드가 고유한 ID를 가지도록 만들었습니다.
public class ThreadLocalExample {
// AtomicInteger를 사용하여 스레드 안전한 ID 생성기를 만든다.
private static final AtomicInteger nextId = new AtomicInteger(0);
// ThreadLocal 변수를 생성하고 initialValue 메소드를 재정의하여 각 스레드마다 고유한 ID를 할당한다.
private static final ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return nextId.getAndIncrement();
}
};
// 현재 스레드의 ID를 반환하는 메서드
public static int getThreadId() {
return threadId.get();
}
static class Task implements Runnable {
@Override
public void run() {
int threadId = getThreadId();
System.out.println("스레드 ID " + threadId + ": 작업 실행 중.");
}
}
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
executor.submit(new Task());
}
executor.shutdown();
}
}위 예시에서 대략적으로 ThreadLocalMap의 상태를 그려보면 다음과 같습니다. ThreadLocalMap은 ThreadLocal 변수를 키로 사용해서 각 스레드별로 저장되는 값을 관리하는 것을 볼 수 있습니다.
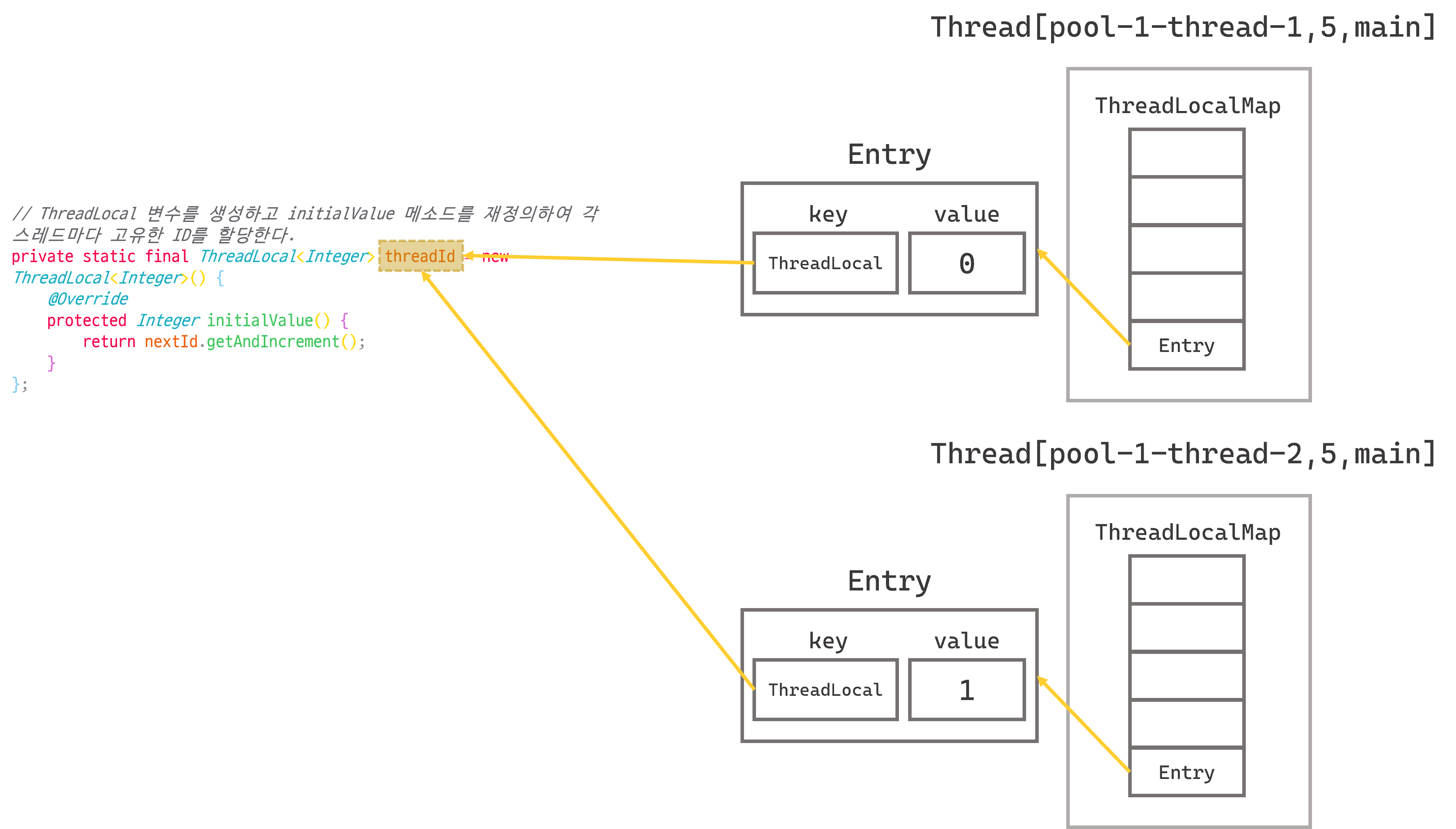
각 스레드마다 고유한 ID를 할당하기 때문에, ThreadLocalMap은 스레드 별로 고유한 ID를 저장하게 됩니다.
주의사항
객체의 수명
ThreadLocal의 값이 더 이상 필요하지 않을 때는 항상 값을 제거해야 합니다. 그렇지 않으면 ThreadLocal에 저장된 객체는 스레드가 죽을 때까지 메모리에서 해제되지 않으므로 메모리 누수가 일어날 수도 있습니다. 따라서 ThreadLocal을 사용한 뒤에는 remove() 메서드를 호출해서 값을 제거해주어야 합니다.
try {
threadLocal.set(value);
/* ... */
} finally {
threadLocal.remove();
}그리고 위의 스레드 ID 예시에서도 살펴봤지만, 스레드 풀을 사용하면 스레드가 재활용될 수 있기 때문에 이전에 설정한 값이 계속 남아있어 원치 않는 결과를 초래할 수 있습니다. 대표적인 예시가 스레드 풀을 사용하는 WAS의 경우인데 이전 요청에서 ThreadLocal에 저장했던 사용자의 정보가 다른 요청에서 유출될 수 있으므로 각별한 주의가 필요합니다.
눈에 보이지 않는 연결 관계
ThreadLocal은 전역 변수가 아니지만 전역 변수처럼 동작할 수 있어서 프로그램 구조에 문제를 일으킬 수 있습니다. 메서드 인자로 값을 전달하는 대신 ThreadLocal을 사용해서 값을 전달하면 프로그램 구조가 허약해질 수 있습니다. 이렇게 되면 메서드 사이의 명시적인 연결 고리가 약해지고 코드의 가독성이 떨어지게 됩니다.
또한 ThreadLocal 변수를 사용하면 객체 간 눈에 보이지 않는 연결 관계가 생기기 쉽습니다. 이로 인해서 코드의 의존성이 증가하고, 프로그램이 예기치 않은 방식으로 동작할 수 있습니다. 따라서 ThreadLocal 변수를 사용할 때는 주의가 필요하며, 객체 간의 의존성을 최소화하고 코드를 명확하게 구현하는 것이 좋습니다.
'프로그래밍 관련 > 자바' 카테고리의 다른 글
| 번외편. ConcurrentHashMap (6) | 2023.04.16 |
|---|---|
| 번외편. CompletableFuture (0) | 2023.04.12 |
| 30편. 스레드(Thread) (3) (0) | 2023.04.07 |
| invokedynamic의 내부 동작 (0) | 2022.05.22 |
| 38편. 레코드(Record) (0) | 2022.05.20 |